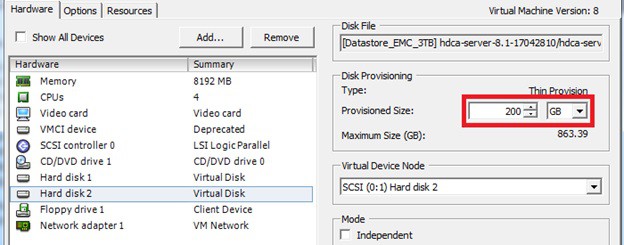
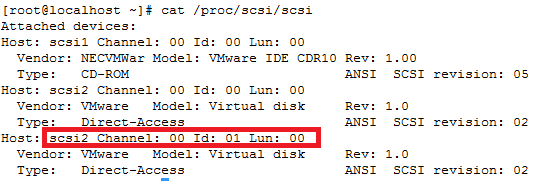
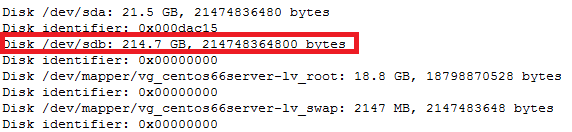
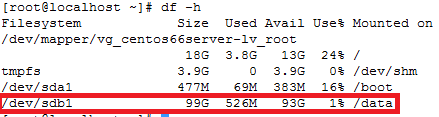
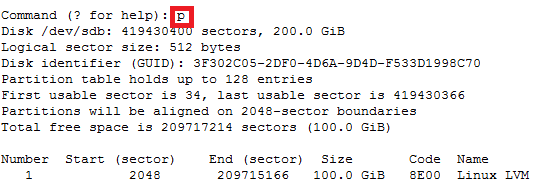
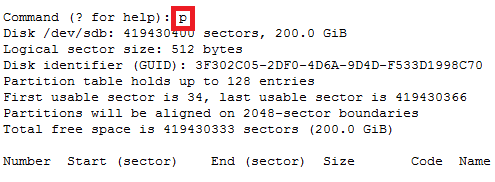
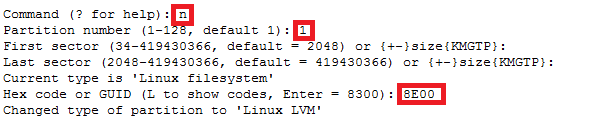
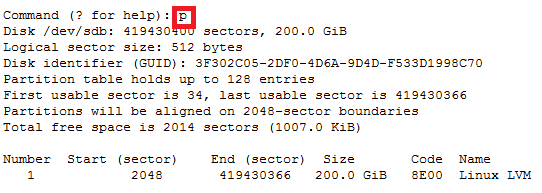
Note: This document is assuming that your capsule server are already configured and your dhcpd service is running and your subnets have been added to the config already.
Manual process:
HOST TAB
1.On the top menu bar click on the HOSTS
Under Create hosts there are a bunch of tabs that need to be filled out.
Name * (This is the name of your vm) – “nick.test1.com”
This value is used also as the host’s primary interface name.
Organisation * Which ever ORG which want the host to live in (LCH)
Location * london
Host Group – We will do this late for now just choose an existing non-prod group.
Deploy on – Bare Metal
Lifecycle Environment Non-Prod
Content View – Select a content view that exists, check under content view
Content Source – leave blank
Interfaces TAB
Type : Interface
MAC address : Grab the mac address from vcenter or login in existing OS and get interface mac-address
Device identifier : en016780032
DNS name “nick.test1.com
Domain : nicktailor.com
IPv4 Subnet: subnet the vlan lives on(this is setup on capsule server)
nick-10.61.120.0-26(10.61.120.0/26)
IPv6 Subnet
IPv4 address : 10.61.120.45
Managed (checked)
Primary (checked)
Provision(checked)
Remote execution(checked)
.
Operating System TAB
Architecture * :x86_64
Operating system *: RHEL Server 7.4
Media SelectionSynced Content All Media
Select the installation media that will be used to provision this host. Choose ‘Synced Content’ for Synced Kickstart Repositories or ‘All Media’ for other media.
Media *: RHE7-cap01 (this is where the repositories live)
Partition table *: RHEL7-TESTING (make sure this attached to a hostgroup and operating sytem) Under HOSTS & CONFIGURE)
PXE loader : PXELinux BIOS (this is for the PXE Boot)
Custom partition table (leave blank unless you want to overide
What ever text(or ERB template) you use in here, would be used as your OS disk layout options If you want to use the partition table option, delete all of the text from this field
Root password : password
Password must be 8 characters or more
Pamameters TAB
Puppet class parameters
Puppet class Name Value Omit
.
Global parameters:
Capsule : nick-cap01.com
Activation_keys: RHEL7-2017-12-PROD
nick-cap01.com
kt_activation_keys: RHEL7-2017-12-Prod
(if you override the default key it shows up below)
puppet_server : nick-pup02.com
.
Host parameters:
Name Value Actions
kt_activation_keys
RHEL7-2017-12-Non-Prod (nonprod)
Additional Information TAB
Owned by: Nick Tailor
Enabled: Include this host within satellite reporting (check this)
Hardware Model
Commen: Blank
.
Next Step – Create a hostgroup
Under Configure select Host Groups( You need a host group in for your deployment to work properly without this is will not work )
Note: Generally its easier to clone an existing hostgroup, change the name and edit the settings to save you time. However for the purposes of this document. We are going to go through the process.
1.Click on Create Host Group (Top right)
Host Group Tab
Parent
Name *: Nick-hax0r-servers (Project name – servers)
Lifecycle Environment: NON-PROD (make sure you have lifecycle environment configured)
Content View : RHEL7-2019-03 (Make sure to select a content view that exists, you can go to content views and look at which it exists and the copy and paste the name exactly)
Content Source: nick-cap01.com(This is the capsule server where the content for the repositories exist for the dev environment, in addition where the subnets are defined that these project servers can dhcp from pxeboot)
Puppet Environment: Non_Production_RHEL7_2019_03_127
Note: (Define this is you have a puppet environment configured with satellite. You will need to have your puppet environment match this content view if you do)
Compute profile : Blank
Puppet Master: Blank
Puppet CA: Blank
OpenSCAP Capsule : Blank
Note: (This is good for pulling server information and vulnerabilities)
Network TAB
Domain: nicktailor.com
IPv4 Subnet: NTC-10.61.120.0-26(10.61.120.0/26)
Note: (These subnets are defined in satellite under Infrastructure and then Subnets)
IPv6 : No Subnet
Realm: Blank
.
Operating System TAB
Architecture: x86_64
Operating system * : RHEL Server 7.4
(Note: This section is very important. You will need to attach the partition table to the operating system under Hosts and Operating System. If you do not when you make your provision template this host group will not be able to see the partition table you created when you choose the OS you want to deploy.
Media Selection Synced Content All Media
Select the installation media that will be used to provision this host. Choose ‘Synced Content’ for Synced Kickstart Repositories or ‘All Media’ for other media.
Media *: RHEL7-nick-cap01
Partition table *: RHEL7-Testing
(Note: This is created under HOSTS and Partition Table)
PXE loader: Blank
Root password: Password (set this for your server to desired setting)
.
Parameters TAB
Global Parameters
Host group parameters:
Name: Value:
Capsule nick-cap01.com
puppet_server nick-pup02.com
Note:(You only need this define i`f you have a puppet server environment configured)
.
Locations TAB
Under Selected Items:
Add London
Organizations TAB
Under Selected Items:
Add organizations you want to have access to the host group
ADD: LCH
.
Activation Keys TAB
Activation keys: RHEL7-2017-12-Non-Prod (this key defines which organization, host group, repositories, life cycle environment and organization the host initially gets registered with. You can manually change these setting after, however its probably good to make a proper key to save you lots of time.
.
Next Step – Created Patition Table
HOSTS and Partition Tables
.
1.Click On Create Parition Table
(Note: Its generally better to clone an exitsing table and edit as needed, however for the purposes of this doc, we will go through the settings) You will also need to add this table to your operating system under Hosts and Operating system for the provision template to work properly)
Template TAB
Name * : GTP-RHEL7-Testing (Name your partition table scheme)
Default
Default templates are automatically added to new organisations and locations
Snippet
Operating system family: RED HAT
Input:
Note: This is a standard lvm setup using ext4 for the OS. If you are going to use dual boot, then you want to change the first 3 lines
zerombr
clearpart –drives=sda –all –initlabel
part /boot –fstype ext4 –size=1024 –asprimary –ondisk=sda
part pv.00 –size=1 –grow –asprimary –ondisk=sda
volgroup vgroot pv.00
logvol / –name=lv_root –vgname=vgroot –size=15360 –fstype ext4
logvol swap –name=lv_swap –vgname=vgroot –size 6144 –fstype swap
logvol /var –name=lv_var –vgname=vgroot –size 10240 –fstype ext4
logvol /opt –name=lv_opt –vgname=vgroot –size 10240 –fstype ext4
logvol /var/tmp –name=lv_var_tmp –vgname=vgroot –size 5120 –fstype ext4 –fsoptions=nodev,nosuid,noexec
logvol /var/log –name=lv_var_log –vgname=vgroot –size 5120 –fstype ext4
logvol /var/log/audit –name=lv_var_log_audit –vgname=vgroot –size 2048 –fstype ext4
logvol /var/coredumps –name=lv_crash –vgname=vgroot –size 16384 –fstype ext4
logvol /tmp –name=lv_tmp –vgname=vgroot –size 5120 –fstype ext4 –fsoptions=nodev,nosuid,noexec
logvol /home –name=lv_home –vgname=vgroot –size 5120 –fstype ext4 –fsoptions=nodev
.
Dual Boot template:
.
Note: Change the drive designation from sda to sdx (x being whatever the new drive designation is) In the example below its /dev/sdc
.
clearpart –drives=sdc –all –initlabel
part /boot –fstype ext4 –size=1024 –asprimary –ondisk=sdc
part pv.00 –size=1 –grow –asprimary –ondisk=sdc
volgroup vgroot pv.00
logvol / –name=lv_root –vgname=vgroot –size=15360 –fstype ext4
logvol swap –name=lv_swap –vgname=vgroot –size 6144 –fstype swap
logvol /var –name=lv_var –vgname=vgroot –size 10240 –fstype ext4
logvol /opt –name=lv_opt –vgname=vgroot –size 10240 –fstype ext4
logvol /var/tmp –name=lv_var_tmp –vgname=vgroot –size 5120 –fstype ext4 –fsoptions=nodev,nosuid,noexec
logvol /var/log –name=lv_var_log –vgname=vgroot –size 5120 –fstype ext4
logvol /var/log/audit –name=lv_var_log_audit –vgname=vgroot –size 2048 –fstype ext4
logvol /var/coredumps –name=lv_crash –vgname=vgroot –size 16384 –fstype ext4
logvol /tmp –name=lv_tmp –vgname=vgroot –size 5120 –fstype ext4 –fsoptions=nodev,nosuid,noexec
logvol /home –name=lv_home –vgname=vgroot –size 5120 –fstype ext4 –fsoptions=nodev
.
Locations TAB
.
Under Selected Items:
ADD: London
.
Organization TAB
.
Under Selected Items:
ADD: NTC
.
.
Next Step – ADD New Partition Table to Operating System
1.Click on HOSTS and Operating Systems
2.Select the OS
a. RHEL 7.2
Note- (This part is important. The way to figure out which OS to choose is to check the which repositories are available on the capsule server defined. Say you chose RHEL7. 4, but the repository doesn’t exist there. The provision template will then choose the default template and your partition template and everything will no longer be there and you could accident deploy on the wrong disk wiping out data potentially)
.
Example if we chose the content view RHEL7-2019-03 and the OS RHEL7.4 in the provision template but on the capsule server. The path shows only 7.5 under that content view, the url would fail during the deployment and revert 7.2 default settings and would use a different partition table if the one you created wasn’t available under the default OS setting.
.
root@nick-cap01:/var/lib/pulp/published/yum/http/repos/NTC/Non-Production/RHEL7-2019-03/content/dist/rhel/server/7/7.5
.
I found its best to use the default OS and then just ensure that yum update is in the kickstart file that is going to be used
.
Will look like this in the kickstart file.
# update all the base packages from the updates repository
yum -t -y -e 0 update
b.Next under Parition Table tab
ii.Add new partition table (GTP-RHEL7-TESTING)
.
Now go back to your New your provision template.
.
Under Hosts and Provision Template.
1.Select your new template (GTP-kickstartprofile-testing)
a.Under Association TAB
i.Ensure the OS RHEL 7.2 is under selected items
b.Under Host Group
ii.Your new Host Group is selected (GTP-servers)
.
Now to set your server to build status so that the PXEboot is able to pick it up on network book.
.
1.Under Hosts and All hosts
2.Search for your host
a.Click on the host nick.test1.com
b.Click on BUILD on the far right (Note this will create the pxeboot file on the capsule server so when you network boot this host it will know which server to deploy the provision templates to.
.
.
Now we can test the deployment from VCENTER
.
1.Under VM’s
a.Find your Vm (nick.test2.com)
b.Open your console on the vm
c.Reboot
i.During the reboot hit f12 for the network boot option.
d.If all goes well the kickstart server should deploy without any intervention and reboot into your OS
.
.
.
.
.
.