
Category: Linux
Varnish 3.0 Setup in HA for Drupal 7 with Redhat (Part 2)
Varnish 3.0 Setup in HA for Drupal 7 using Redhat Servers

So now that you have read the Varnish and how it works posting of my blog. We can begin with how I went about setting my varnish. The Diagram above is basically the same setup we had.
Since we were using redhat and this was going into production eventually. I decided it was best to stick to repos, now keep in mind you don’t have to do this. You can go ahead and compile your own version if you wish. For the purpose of my tutorial, we’re going to use third party repo called EPEL.
- Installing Varnish 3.0 on Redhat
- This configuration is based on lullobot’s setup, with some tweaks and stuff I found that he forgot to mention which I spent hours learning.
Varnish is distributed in the EPEL (Extra Packages for Enterprise Linux) package repositories. However, while EPEL allows new versions to be distributed, it does not allow for backwards-incompatible changes. Therefore, new major versions will not hit EPEL and it is therefore not necessarily up to date. If you require a newer major version than what is available in EPEL, you should use the repository provided by varnish-cache.org.
To use the varnish-cache.org repository, run
rpm --nosignature -i http://repo.varnish-cache.org/redhat/varnish-3.0/el5/noarch/varnish-release-3.0-1.noarch.rpm
and then run
yum install varnish
The --no-signature is only needed on initial installation, since the Varnish GPG key is not yet in the yum keyring
–Note: So after you install it, you will notice that the daemon will not start. Total piss off right? This is because you need to configure a few things based on the resources you have available. This is explained all my Varnish how it works post, which you have already read 😛
2. So, we need to get varnish running first before we can play with it this is done /etc/sysconfig/varnish. These are the settings I used for my configuration. My VM’s had 2 CPU’s and 4 gigs of ram each.
If you want to know what these options do, go read my previous post. It would take too long to explain each flag in this post, and this will get boring hence why I wrote it in two parts. Save the file and then start varnish /etc/init.d/varnish start. If it doesn’t start you have a mistake somewhere in here.
DAEMON_OPTS=”-a *:80,*:443 \
-T 127.0.0.1:6082 \
-f /etc/varnish/default.vcl \
-u varnish -g varnish \
-S /etc/varnish/secret \
-p thread_pool_add_delay=<Number of CPU cores> \\
-p thread_pools=Number of CPU cores\
-p thread_pool_max=1500 \
-p listen_depth=2048 \
# -p lru_interval=1500 \
-h classic,169313 \
-p obj_workspace=4096 \
-p connect_timeout=600 \
-p sess_workspace=50000 \
-p max_restarts=6 \
-s malloc,2G”
3. now that varnish is started you need to setup the VCL which it will read. The better you understand how your application works, the better you will be able to fine time the way the cache works. There is no one way to do this. This is simply how I went about it.
VCL Configuration
The VCL file is the main location for configuring Varnish and it’s where we’ll be doing the majority of our changes. It’s important to note that Varnish includes a large set of defaults that are always automatically appended to the rules that you have specified. Unless you force a particular command like “pipe”, “pass”, or “lookup”, the defaults will be run. Varnish includes an entirely commented-out default.vcl file that is for reference.
So this configuration will be connecting to two webserver backends. Each webserver has a health probe which the VCL is checking. If the probe fails it removes the webserver from the caching round robin. The cache is also updating every 30 seconds as long as one of the webservers is up and running. If both webservers go down it will server objects from the cache up to 12 hours, this is varied depending on how you configure it.
http://www.nicktailor.com/files/default.vcl
Now what some people do is they have a php script that sits on the webservers, which varnish will run and if everything passes the web server stays in the pool. I didn’t bother to do it this way. I setup a website that connected to a database and had the health probe just look for status 200 code. If the page came up web server stayed in the pool. if it didn’t it will it drop it.
# Define the list of backends (web servers).
# Port 80 Backend Servers
backend web1 { .host = “status.nicktailor.com”; .probe = { .url = “/”; .interval = 5s; .timeout = 1s; .window = 5;.threshold = 3; }}
backend web2 { .host = “status.nicktailor.com”; .probe = { .url = “/”; .interval = 5s; .timeout = 1s; .window = 5;.threshold = 3; }}
Caching Even if Apache Goes Down
So a few people have written articles about this and say how to do it, but it took me a bit to get this working.
Even in an environment where everything has a redundant backup, it’s possible for the entire site to go “down” due to any number of causes. A programming error, a database connection failure, or just plain excessive amounts of traffic. In such scenarios, the most likely outcome is that Apache will be overloaded and begin rejecting requests. In those situations, Varnish can save your bacon with theGrace period. Apache gives Varnish an expiration date for each piece of content it serves. Varnish automatically discards outdated content and retrieves a fresh copy when it hits the expiration time. However, if the web server is down it’s impossible to retrieve the fresh copy. “Grace” is a setting that allows Varnish to serve up cached copies of the page even after the expiration period if Apache is down. Varnish will continue to serve up the outdated cached copies it has until Apache becomes available again.
To enable Grace, you just need to specify the setting in vcl_recv and invcl_fetch:
# Respond to incoming requests.
sub vcl_recv {
# Allow the backend to serve up stale content if it is responding slowly.
set req.grace = 6h;
}
# Code determining what to do when serving items from the Apache servers.
sub vcl_fetch {
# Allow items to be stale if needed.
set beresp.grace = 6h;
}
Note- The missing piece to this is the most important piece, without the ttl below if webservers go down, after like 2 mins your backend will show an error page, because by default the ttl for objects to stay in the cache when the webservers aka backend go down is set extremely low. Everyone seems to forget to mention this crucial piece of information.
# Code determining what to do when serving items from the Apache servers.
sub vcl_fetch {
# Allow items to be stale if needed.
set beresp.grace = 24h;
set beresp.ttl = 6h;
}
Just remember: while the powers of grace are awesome, Varnish can only serve up a page that it has already received a request for and cached. This can be a problem when you’re dealing with authenticated users, who are usually served customized versions of pages that are difficult to cache. If you’re serving uncached pages to authenticated users and all of your web servers die, the last thing you want is to present them with error messages. Instead, wouldn’t it be great if Varnish could “fall back” to the anonymous pages that it does have cached until the web servers came back? Fortunately, it can — and doing this is remarkably easy! Just add this extra bit of code into the vcl_recv sub-routine:
# Respond to incoming requests.
sub vcl_recv {
# …code from above.
# Use anonymous, cached pages if all backends are down.
if (!req.backend.healthy) {
unset req.http.Cookie;
}
}
Varnish sets a property req.backend.health if any web server is available. If all web servers go down, this flag becomes FALSE. Varnish will strip the cookie that indicates a logged-in user from incoming request, and attempt to retrieve an anonymous version of the page. As soon as one server becomes healthy again, Varnish will quit stripping the cookie from incoming requests and pass them along to Apache as normal.
Making Varnish Pass to Apache for Uncached Content
Often when configuring Varnish to work with an application like Drupal, you’ll have some pages that should absolutely never be cached. In those scenarios, you can easily tell Varnish to not cache those URLs by returning a “pass” statement.
# Do not cache these paths.
if (req.url ~ “^/status\.php$” ||
req.url ~ “^/update\.php$” ||
req.url ~ “^/ooyala/ping$” ||
req.url ~ “^/admin/build/features” ||
req.url ~ “^/info/.*$” ||
req.url ~ “^/flag/.*$” ||
req.url ~ “^.*/ajax/.*$” ||
req.url ~ “^.*/ahah/.*$”) {
return (pass);
}
Varnish will still act as an intermediary between requests from the outside world and your web server, but the “pass” command ensures that it will always retrieve a fresh copy of the page.
In some situations, though, you do need Varnish to give the outside world a direct connection to Apache. Why is it necessary? By default, Varnish will always respond to page requests with an explicitly specified “content-length”. This information allows web browsers to display progress indicators to users, but some types of files don’t have predictable lengths. Streaming audio and video, and any files that are being generated on the server and downloaded in real-time, are of unknown size, and Varnish can’t provide the content-length information. This is often encountered on Drupal sites when using the Backup and Migrate module, which creates a SQL dump of the database and sends it directly to the web browser of the user who requested the backup.
To keep Varnish working in these situations, it must be instructed to “pipe” those special request types directly to Apache.
# Pipe these paths directly to Apache for streaming.
if (req.url ~ “^/admin/content/backup_migrate/export”) {
return (pipe);
}
Just remember: while the powers of grace are awesome, Varnish can only serve up a page that it has already received a request for and cached. This can be a problem when you’re dealing with authenticated users, who are usually served customized versions of pages that are difficult to cache. If you’re serving uncached pages to authenticated users and all of your web servers die, the last thing you want is to present them with error messages. Instead, wouldn’t it be great if Varnish could “fall back” to the anonymous pages that it does have cached until the web servers came back? Fortunately, it can — and doing this is remarkably easy! Just add this extra bit of code into the vcl_recv sub-routine:
# Respond to incoming requests.
sub vcl_recv {
# …code from above.
# Use anonymous, cached pages if all backends are down.
if (!req.backend.healthy) {
unset req.http.Cookie;
}
}
Varnish sets a property req.backend.health if any web server is available. If all web servers go down, this flag becomes FALSE. Varnish will strip the cookie that indicates a logged-in user from incoming request, and attempt to retrieve an anonymous version of the page. As soon as one server becomes healthy again, Varnish will quit stripping the cookie from incoming requests and pass them along to Apache as normal.
Making Varnish Pass to Apache for Uncached Content
Often when configuring Varnish to work with an application like Drupal, you’ll have some pages that should absolutely never be cached. In those scenarios, you can easily tell Varnish to not cache those URLs by returning a “pass” statement.
# Do not cache these paths.
if (req.url ~ “^/status\.php$” ||
req.url ~ “^/update\.php$” ||
req.url ~ “^/ooyala/ping$” ||
req.url ~ “^/admin/build/features” ||
req.url ~ “^/info/.*$” ||
req.url ~ “^/flag/.*$” ||
req.url ~ “^.*/ajax/.*$” ||
req.url ~ “^.*/ahah/.*$”) {
return (pass);
}
Varnish will still act as an intermediary between requests from the outside world and your web server, but the “pass” command ensures that it will always retrieve a fresh copy of the page.
In some situations, though, you do need Varnish to give the outside world a direct connection to Apache. Why is it necessary? By default, Varnish will always respond to page requests with an explicitly specified “content-length”. This information allows web browsers to display progress indicators to users, but some types of files don’t have predictable lengths. Streaming audio and video, and any files that are being generated on the server and downloaded in real-time, are of unknown size, and Varnish can’t provide the content-length information. This is often encountered on Drupal sites when using the Backup and Migrate module, which creates a SQL dump of the database and sends it directly to the web browser of the user who requested the backup.
To keep Varnish working in these situations, it must be instructed to “pipe” those special request types directly to Apache.
# Pipe these paths directly to Apache for streaming.
if (req.url ~ “^/admin/content/backup_migrate/export”) {
return (pipe);
}
How to view the log and what to look for
varnishlog |grep -i -v ng (This will output a one page out of the log so you can see it without it going all over the place)
- One of the key things to look for is if your back end is healthy, it should show that in this log, if it does not show this, then something is still wrong. I have jotted down what it should look like below.
Every poll is recorded in the shared memory log as follows:
NB: subject to polishing before 2.0 is released!
0 Backend_health - b0 Still healthy 4--X-S-RH 9 8 10 0.029291 0.030875 HTTP/1.1 200 Ok
The fields are:
- 0 — Constant
- Backend_health — Log record tag
- – — client/backend indication (XXX: wrong! should be ‘b’)
- b0 — Name of backend (XXX: needs qualifier)
- two words indicating state:
- “Still healthy”
- “Still sick”
- “Back healthy”
- “Went sick”
Notice that the second word indicates present state, and the first word == “Still” indicates unchanged state.
- 4–X-S-RH — Flags indicating how the latest poll went
- 4 — IPv4 connection established
- 6 — IPv6 connection established
- x — Request transmit failed
- X — Request transmit succeeded
- s — TCP socket shutdown failed
- S — TCP socket shutdown succeeded
- r — Read response failed
- R — Read response succeeded
- H — Happy with result
- 9 — Number of good polls in the last .window polls
- 8 — .threshold (see above)
- 10 — .window (see above)
- 0.029291 — Response time this poll or zero if it failed
- 0.030875 — Exponential average (r=4) of responsetime for good polls.
- HTTP/1.1 200 Ok — The HTTP response from the backend.
- Varnishhist – The varnishhist utility reads varnishd(1) shared memory logs and presents a continuously updated histogram show- ing the distribution of the last N requests by their processing. The value of N and the vertical scale are dis- played in the top left corner. The horizontal scale is logarithmic. Hits are marked with a pipe character (“|”), and misses are marked with a hash character (“#”)
- Varnishtop – The varnishtop utility reads varnishd(1) shared memory logs and presents a continuously updated list of the most commonly occurring log entries. With suitable filtering using the -I, -i, -X and -x options, it can be used to display a ranking of requested documents, clients, user agents, or any other information which is recorded in the log.
Warming up the Varnish Cache
Example:
wget –mirror -r -N -D http://www.nicktailor.com – You will need to check the wget flags I did this off memory
- Varnishreplay -The varnishreplay utility parses varnish logs and attempts to reproduce the traffic. It is typcally used to warm up caches or various forms of testing.The following options are available:
-abackend Send the traffic over tcp to this server, specified by an address and a port. This option is mandatory. Only IPV4 is supported at this time. -D Turn on debugging mode. -r file Parse logs from this file. The input file has to be from a varnishlog of the same version as the varnishreplay binary. This option is mandatory.
Understanding how Varnish works (Part 1)
I put this post together because you kind of need to understand these things before you try and setup varnish, otherwise you will be trial and error like I was which took a bit a longer. If I had known these things it would of helped.
Varnish 3.0 How it works
I am writing this blog post because when I setup Varnish is very painful to learn, because varnish does not work out of the box. It needs to be configured to even start on redhat. Although there are some great posts out there on how to setup, they all fail to mention key details that every newb wants to know and ends up digging all over the net to find. So I have decided to save everyone the trouble and I’m writing it from beginning to end with descriptions and why and how it all works.
Understanding The Architecture and process model

Varnish has two main processes: the management process and the child process. The management process apply configuration changes (VCL and parameters), compile VCL, monitor Varnish, initialize Varnish and provides a command line interface, accessible either directly on the terminal or through a management interface.
The management process polls the child process every few seconds to see if it’s still there. If it doesn’t get a reply within a reasonable time, the management process will kill the child and start it back up again. The same happens if the child unexpectedly exits, for example from a segmentation fault or assert error.
This ensures that even if Varnish does contain a critical bug, it will start back up again fast. Usually within a few seconds, depending on the conditions.
The child process
The child process consist of several different types of threads, including, but not limited to:
Acceptor thread to accept new connections and delegate them. Worker threads – one per session. It’s common to use hundreds of worker threads. Expiry thread, to evict old content from the cache Varnish uses workspaces to reduce the contention between each thread when they need to acquire or modify memory. There are multiple workspaces, but the most important one is the session workspace, which is used to manipulate session data. An example is changing www.example.com to example.com before it is entered into the cache, to reduce the number of duplicates.
It is important to remember that even if you have 5MB of session workspace and are using 1000 threads, the actual memory usage is not 5GB. The virtual memory usage will indeed be 5GB, but unless you actually use the memory, this is not a problem. Your memory controller and operating system will keep track of what you actually use.
To communicate with the rest of the system, the child process uses a shared memory log accessible from the file system. This means that if a thread needs to log something, all it has to do is grab a lock, write to a memory area and then free the lock. In addition to that, each worker thread has a cache for log data to reduce lock contention.
The log file is usually about 90MB, and split in two. The first part is counters, the second part is request data. To view the actual data, a number of tools exist that parses the shared memory log. Because the log-data is not meant to be written to disk in its raw form, Varnish can afford to be very verbose. You then use one of the log-parsing tools to extract the piece of information you want – either to store it permanently or to monitor Varnish in real-time.
All of this is logged to syslog. This makes it crucially important to monitor the syslog, otherwise you may never even know unless you look for them, because the perceived downtime is so short.
VCL compilation
Configuring the caching policies of Varnish is done in the Varnish Configuration Language (VCL). Your VCL is then interpreted by the management process into to C and then compiled by a normal C compiler – typically gcc. Lastly, it is linked into the running Varnish instance.
As a result of this, changing configuration while Varnish is running is very cheap. Varnish may want to keep the old configuration around for a bit in case it still has references to it, but the policies of the new VCL takes effect immediately.
Because the compilation is done outside of the child process, there is no risk of affecting the running Varnish by accidentally loading an ill-formated VCL.
A compiled VCL file is kept around until you restart Varnish completely, or until you issue vcl.discard from the management interface. You can only discard compiled VCL files after all references to them are gone, and the amount of references left is part of the output of vcl.list.
Storage backends
Varnish supports different methods of allocating space for the cache, and you choose which one you want with the -s argument.
file
malloc
persistent (experimental)
Rule of thumb: malloc if it fits in memory, file if it doesn’t
Expect around 1kB of overhead per object cached
They approach the same basic problem from two different angles. With the malloc-method, Varnish will request the entire size of the cache with a malloc() (memory allocation) library call. The operating system divides the cache between memory and disk by swapping out what it can’t fit in memory.
The alternative is to use the file storage backend, which instead creates a file on a filesystem to contain the entire cache, then tell the operating system through the mmap() (memory map) system call to map the entire file into memory if possible.
The file storage method does not retain data when you stop or restart Varnish! This is what persistent storage is for. When -s file is used, Varnish does not keep track of what is written to disk and what is not. As a result, it’s impossible to know whether the cache on disk can be used or not — it’s just random data. Varnish will not (and can not) re-use old cache if you use -s file.
While malloc will use swap to store data to disk, file will use memory to cache the data instead. Varnish allow you to choose between the two because the performance of the two approaches have varied historically.
The persistent storage backend is similar to file, but experimental. It does not yet gracefully handle situations where you run out of space. We only recommend using persistent if you have a large amount of data that you must cache and are prepared to work with us to track down bugs.
Tunable parameters
In the CLI:
param.show -l
Varnish has many different parameters which can be adjusted to make Varnish act better under specific workloads or with specific software and hardware setups. They can all be viewed with param.show in the management interface and set with the -p option passed to Varnish – or directly in the management interface.
Remember that changes made in the management interface are not stored anywhere, so unless you store your changes in a startup script, they will be lost when Varnish restarts.
The general advice with regards to parameters is to keep it simple. Most of the defaults are very good, and even though they might give a small boost to performance, it’s generally better to use safe defaults if you don’t have a very specific need.
A few hidden commands exist in the CLI, which can be revealed with help -d. These are meant exclusively for development or testing, and many of them are downright dangerous. They are hidden for a reason, and the only exception is perhaps debug.health, which is somewhat common to use.
The shared memory log
Varnish’ shared memory log is used to log most data. It’s sometimes called a shm-log, and operates on a round-robin capacity.
There’s not much you have to do with the shared memory log, except ensure that it does not cause I/O. This is easily accomplished by putting it on a tmpfs.
This is typically done in ‘/etc/fstab’, and the shmlog is normally kept in ‘/var/lib/varnish’ or equivalent locations. All the content in that directory is safe to delete.
The shared memory log is not persistent, so do not expect it to contain any real history.
The typical size of the shared memory log is 80MB. If you want to see old log entries, not just real-time, you can use the -d argument for varnishlog: varnishlog -d.
Warning: Some packages will use -s file by default with a path that puts the storage file in the same directory as the shmlog. You want to avoid this.
Threading model
The child process runs multiple threads
Worker threads are the bread and butter of the Varnish architecture
Utility-threads
Balance
The child process of Varnish is where the magic takes place. It consists of several distinct threads performing different tasks. The following table lists some interesting threads, to give you an idea of what goes on. The table is not complete.Thread-name Amount of threads Task
cache-worker One per active connection Handle requests
cache-main One Startup
ban lurker One Clean bans
acceptor One Accept new connections
epoll/kqueue Configurable, default: 2 Manage thread pools
expire One Remove old content
backend poll One per backend poll Health checks
Most of the time, we only deal with the cache-worker threads when configuring Varnish. With the exception of the amount of thread pools, all the other threads are not configurable.
For tuning Varnish, you need to think about your expected traffic. The thread model allows you to use multiple thread pools, but time and experience has shown that as long as you have 2 thread pools, adding more will not increase performance.
The most important thread setting is the number of worker threads.
Note: If you run across tuning advice that suggests running one thread pool for each CPU core, res assured that this is old advice. Experiments and data from production environments have revealed that as long as you have two thread pools (which is the default), there is nothing to gain by increasing the number of thread pools.
Threading parameters
Thread pools can safely be ignored
Maximum: Roughly 5000 (total)
Start them sooner rather than later
Maximum and minimum values are per thread pool
Details of threading parameters
While most parameters can be left to the defaults, the exception is the number of threads.Varnish will use one thread for each session and the number of threads you let Varnish use is directly proportional to how many requests Varnish can serve concurrently.The available parameters directly related to threads are:Parameter
Default value
thread_pool_add_delay 2 [milliseconds]
thread_pool_add_threshold 2 [requests]
thread_pool_fail_delay 200 [milliseconds]
thread_pool_max 500 [threads]
thread_pool_min 5 [threads]
thread_pool_purge_delay 1000 [milliseconds]
thread_pool_stack 65536 [bytes]
thread_pool_timeout 300 [seconds]
thread_pools 2 [pools]
thread_stats_rate 10 [requests]
Among these, thread_pool_min and thread_pool_max are most important. The thread_pools parameter is also of some importance, but mainly because it is used to calculate the final number of threads.
Varnish operates with multiple pools of threads. When a connection is accepted, the connection is delegated to one of these thread pools. The thread pool will further delegate the connection to available thread if one is available, put the connection on a queue if there are no available threads or drop the connection if the queue is full. By default, Varnish uses 2 thread pools, and this has proven sufficient for even the most busy Varnish server.
For the sake of keeping things simple, the current best practice is to leave thread_pools at the default 2 [pools].
Number of threads
Varnish has the ability to spawn new worker threads on demand, and remove them once the load is reduced. This is mainly intended for traffic spikes. It’s a better approach to try to always keep a few threads idle during regular traffic than it is to run on a minimum amount of threads and constantly spawn and destroy threads as demand changes. As long as you are on a 64-bit system, the cost of running a few hundred threads extra is very limited.
The thread_pool_min parameter defines how many threads will be running for each thread pool even when there is no load. thread_pool_max defines the maximum amount of threads that will be used per thread pool.
The defaults of a minimum of 5 [threads] and maximum 500 [threads] threads per thread pool and 2 [pools] will result in:
At any given time, at least 5 [threads] * 2 [pools] worker threads will be running
No more than 500 [threads] * 2 [pools] threads will run.
We rarely recommend running with more than 5000 threads. If you seem to need more than 5000 threads, it’s very likely that there is something not quite right about your setup, and you should investigate elsewhere before you increase the maximum value.
For minimum, it’s common to operate with 500 to 1000 threads minimum (total). You can observe if this is enough through varnishstat, by looking at the N queued work requests (n_wrk_queued) counter over time. It should be fairly static after startup.
Timing thread growth
Varnish can use several thousand threads, and has had this capability from the very beginning. Not all operating system kernels were prepared to deal with this, though, so the parameter thread_pool_add_delay was added which ensures that there is a small delay between each thread that spawns. As operating systems have matured, this has become less important and the default value of thread_pool_add_delay has been reduced dramatically, from 20ms to 2ms.
There are a few, less important parameters related to thread timing. The thread_pool_timeout is how long a thread is kept around when there is no work for it before it is removed. This only applies if you have more threads than the minimum, and is rarely changed.
An other is the thread_pool_fail_delay, which defines how long to wait after the operating system denied us a new thread before we try again.
System parameters
As Varnish has matured, fewer and fewer parameters require tuning. The sess_workspace is one of the parameters that could still pose a problem.
sess_workspace – incoming HTTP header workspace (from client)
Common values range from the default of 16384 [bytes] to 10MB
ESI typically requires exponential growth Remember: It’s all virtual – not physical memory.
Workspaces are some of the things you can change with parameters. The session workspace is how much memory is allocated to each HTTP session for tasks like string manipulation of incoming headers. It is also used to modify the object returned from a web server before the precise size is allocated and the object is stored read-only.
Some times you may have to increase the session workspace to avoid running out of workspace.
As most of the parameters can be left unchanged, we will not go through all of them, but take a look at the list param.show gives you to get an impression of what they can do.
TimersParameter Default Description Scope
connect_timeout 0.700000 [s] OS/network latency Backend
first_byte_timeout 60.000000 [s] Page generation? Backend
between_bytes_timeout 60.000000 [s] Hiccoughs? Backend
send_timeout 60 [seconds] Client-in-tunnel Client
sess_timeout 5 [seconds] keep-alive timeout Client
cli_timeout 10 [seconds] Management thread->child Management
The timeout-parameters are generally set to pretty good defaults, but you might have to adjust them for strange applications. The connection timeout is tuned for a geographically close web server, and might have to be increased if your Varnish server and web server are not close.
Keep in mind that the session timeout affects how long sessions are kept around, which in turn affects file descriptors left open. It is not wise to increase the session timeout without taking this into consideration.
The cli_timeout is how long the management thread waits for the worker thread to reply before it assumes it is dead, kills it and starts it back up. The default value seems to do the trick for most users today.
Now that you have read this you can go read My
Varnish Configuration for Drupal in HA on Redhat
How to jail users via sftp on Drupal Servers using Aegir
|
How to jail users via sftp on Drupal Servers
|
You will need to ensure your openssh server your running is at least 5.1 If it not then please check out “How to jail subdomain sftp users via chroot with plesk” in my blog, it will have instructions on how to update your openssh if your running redhat or any similar OS.
#Subsystem sftp /usr/libexec/openssh/sftp-server
Match Group sftp
ChrootDirectory %h
ForceCommand internal-sftp
AllowTcpForwarding no
====================================
-# usermod -s /bin/false joe (change the bash of the user)
/dev/mapper/VGroot-LVroot on / type ext3 (rw)
proc on /proc type proc (rw)
sysfs on /sys type sysfs (rw)
devpts on /dev/pts type devpts (rw,gid=5,mode=620)
/dev/sda1 on /boot type ext3 (rw)
tmpfs on /dev/shm type tmpfs (rw)
/dev/mapper/VGroot-LVlocal on /local type ext3 (rw)
none on /proc/sys/fs/binfmt_misc type binfmt_misc (rw)
sunrpc on /var/lib/nfs/rpc_pipefs type rpc_pipefs (rw)
WEBI_NASprod:/vol/WEBI_DpProdConfig/www_config on /www_config type nfs (rw,addr=10.90.20.6)
WEBI_NASprod:/vol/WEBI_DpProdData/www_data on /www_data type nfs (rw,addr=10.90.20.6)
/www_data/sites/drupal-6.19/sites/test.com/webcam on /home/webcam/webcam type none (rw,bind)
/www_data/sites/drupal-6.19/sites/test.com/pharmdprivate on /home/pharmsci/pharmdprivate type none (rw,bind)
/www_data/sites/drupal-6.19/sites/pharmacy.ubc.ca/jailed on /home/joe/jailed type none (rw,bind) <——
Jail Secondary FTP/Webuser Accounts with Plesk via SFTP
How to Jail Secondary FTP/Webuser Accounts with Plesk via SFTP
1.Log into Plesk and Create Secondary (“WebUser” inside plesk)user/password (You need to do this so the client can update the password for the user from the GUI)
2.Mkdir /home/newuseryoucreatedinplesk (since you created the user in plesk, the user homedirectory will need to manually created for jailing purposes)
eg. Mkdir /home/superman
3.? Next you want to do the following:
-# usermod -G sftp superman (add the user)
-# usermod -s /bin/false superman (change the bash of the user)
-# chmod -R root:root /home/superman (parent directory has to be owned by root for chroot)
-# chmod 755 /home/superman (Permissions on parent directory has to be 755 for sftp to work via chroot)
4. Edit /etc/passwd file and change the directory path of superman to /home/superman (You need to do this since plesk created the user, do not change the UID as this may be saved somewhere in plesk)
eg. superman:x:10034:2522::/home/superman:/bin/false
5. Now you are going to mount the directory that you wanted the user jailed into to the new users home directory
#- Mount –bind <fullpathofdirectoryyouwanttojailuser> <pathtonewusershomdirectory>
Eg.
Mount –bind /www_data/test.com/httpdocs/jailed /home/superman/jailed
Note:so I create this file give it +x permissions and add it to /etc/rc.local so that if the server reboots you don’t loose your mounts.
6. Add the above line to /etc/init.d/sftpjailedmounts.sh <–this is so if you reboot the server the mounts arent lost, this file is loaded by /etc/rc.local
7. Now your going to change the permissions inside their home directory so the sftp user will be able to ftp files
#- chown superman:sftp /home/superman/jailed
8. Test and Ensure you can update the password from plesk admin panel for the client
If you want to see your mount simply type mount and you will them.
eg.
[root@test]# mount
/dev/mapper/VGroot-LVroot on / type ext3 (rw)
proc on /proc type proc (rw)
sysfs on /sys type sysfs (rw)
devpts on /dev/pts type devpts (rw,gid=5,mode=620)
/dev/sda1 on /boot type ext3 (rw)
tmpfs on /dev/shm type tmpfs (rw)
/dev/mapper/VGroot-LVlocal on /local type ext3 (rw)
none on /proc/sys/fs/binfmt_misc type binfmt_misc (rw)
sunrpc on /var/lib/nfs/rpc_pipefs type rpc_pipefs (rw)
WEBI_NASdevl:/vol/WEBI_VerfConfig/www_config on /www_config type nfs (rw,addr=10.90.20.8)
WEBI_NASdevl:/vol/WEBI_VerfData/www_data on /www_data type nfs (rw,addr=10.90.20.8)
tmpfs on /usr/local/psa/handlers/before-local type tmpfs (rw)
tmpfs on /usr/local/psa/handlers/before-queue type tmpfs (rw)
tmpfs on /usr/local/psa/handlers/before-remote type tmpfs (rw)
tmpfs on /usr/local/psa/handlers/info type tmpfs (rw)
tmpfs on /usr/local/psa/handlers/spool type tmpfs (rw,mode=0770,uid=2021,gid=31)
/www_data/test.com/httpdocs/jailed on /home/superman/jailed type none (rw,bind)<——
Jailing subdomain SFTP users via chroot with Plesk
Since openssh 4.x does not support chroot via sftp, we need to upgrade openssh on the server in the following manner indicated below if your running plesk,in order for you to be able to jail subdomain users via sftp. (this works with plesk 9 and 10), however in plesk 10 the subdomain user no longer has httpdocs folder and you need to manually re-create this for this fix to work.
1. You have remove the openssh packages currently installed without breaking the plesk dependancies(do not use yum remove)
#rpm -e –nodeps openssh*
2. Next install openssh5 which support chrootdirecorty via sftp run the following
wget http://fs12.vsb.cz/hrb33/el5/hrb-ssh/stable/x86_64/openssh-5.1p1-3.el5.hrb.x86_64.rpm
wget http://fs12.vsb.cz/hrb33/el5/hrb-ssh/stable/x86_64/openssh-askpass-5.1p1-3.el5.hrb.x86_64.rpm
wget http://fs12.vsb.cz/hrb33/el5/hrb-ssh/stable/x86_64/openssh-clients-5.1p1-3.el5.hrb.x86_64.rpm
wget http://fs12.vsb.cz/hrb33/el5/hrb-ssh/stable/x86_64/openssh-server-5.1p1-3.el5.hrb.x86_64.rpm
To install new openssh rpm’s
-#rpm -Uvh openssh*
Here are the unofficial openssh5 rpms for CentOS5 and RHEL5 :
==============================================================
http://fs12.vsb.cz/hrb33/el5/hrb-ssh/stable/i386/
http://fs12.vsb.cz/hrb33/el5/hrb-ssh/stable/x86_64/
==============================================================
updated sshd_config with the following lines below and start ssh, if you restart ssh you will loose the shell window, because the server will try to restart the ssh daemon you just uninstalled. If you just start ssh, it will start the new daemon, and you should maintain the current shell window.
http://www.techrepublic.com/blog/opensource/chroot-users-with-openssh-an-easier-way-to-confine-users-to-their-home-directories/229
=====================================
# override default of no subsystems
Subsystem sftp /usr/libexec/openssh/sftp-server
#Subsystem sftp internal-sftp
Match Group sftp
ChrootDirectory %h
ForceCommand internal-sftp
AllowTcpForwarding no
=====================================
2. add the group sftp by running “groupadd sftp”
3. login into plesk
-create subdomain, ensure you create the secondary ftp account under the subdomain
-check to see that ftp works on 21 if applicable
4. For SSH to work for the secondary user (non jailed)
copy var, usr, tmp, lib, etc, dev, bin
cp -R /www_data/superman.com/var /www_data/superman.com/subdomains/clarkkent
http://forum.parallels.com/showthread.php?t=73191
5. To Jail the users via SFTP into their homedirectory(note this disables the ability to shell in via the secondary user via shell and only allows sftp)
-# usermod -G sftp test2
-# usermod -s /bin/false joe
-# chown root:root /www_data/superman.com/subdomains/clarkkent(the directory you want to jail needs to be owned by root in order to chroot via sftp up to
the parent directory, inside the end directory joe can own the files in this example.)
-# chmod 0755 /www_data/superman.com/subdomains/clarkkent
http://www.techrepublic.com/blog/opensource/chroot-users-with-openssh-an-easier-way-to-confine-users-to-their-home-directories/229
Using Keepalived for Mysql Failover with Master to Master Replication
Hello,
I’m sure many people are wondering how to do this. So I decided to write this up on how I setup the architecture. This also for people who cant use mysql multimaster, because the application they are using doesn’t “offically” support mysql multimaster. If it does, you should look at that avenue before attempting this type of setup 🙂
Its pretty awesome, hope it helps you.
I did not do VRRP failover, which is what some people on the net say to do. This would mean that your VIP would be bound to one server and require an ARP for it to failover to the secondary in a failover scenerio, for mysql this is verrrrrry bad especially in a production high traffic site. In my setup the VIP is bound to both DB’s and will NOT require an ARP for failover.
At the time I wrote this VMAC support was not included in keepalived and it’s just starting to come out in keepalived, however still in its infancy and I don’t recommend trying it unless you’ve tested it thoughorly. Also I did this setup using Virtual Machines in a Production Environment for a University and it worked flawlessly.
Architecture Setup will consist of
–Two LVS Pair Doing Direct Route
–Two MYSQL DB servers doing MASTER TO MASTER replication in fail over scenerio with replication synch and failure protection
–Keepalived will be using a custom misc_chk script which does a TCP, PORT, MYSQL SERVICE RUNNING, and TABLE WRITE check. Should this fail 3 times, it fails to the secondary DB.
-Setting mysql backups as well, you will be able to do backups and restores without breaking replication or stopping mysql.
DIRECT ROUTE
– The virtual IP address is shared by real servers and the load balancer. The load balancer has an interface configured with the virtual IP address too, which is used to accept request packets, and it directly route the packets to the chosen servers. All the real servers have their non-arp alias interface configured with the virtual IP address or redirect packets destined for the virtual IP address to a local socket, so that the real servers can process the packets locally. The load balancer and the real servers must have one of their interfaces physically linked by a HUB/Switch. The architecture of virtual server via direct routing is illustrated as follows:
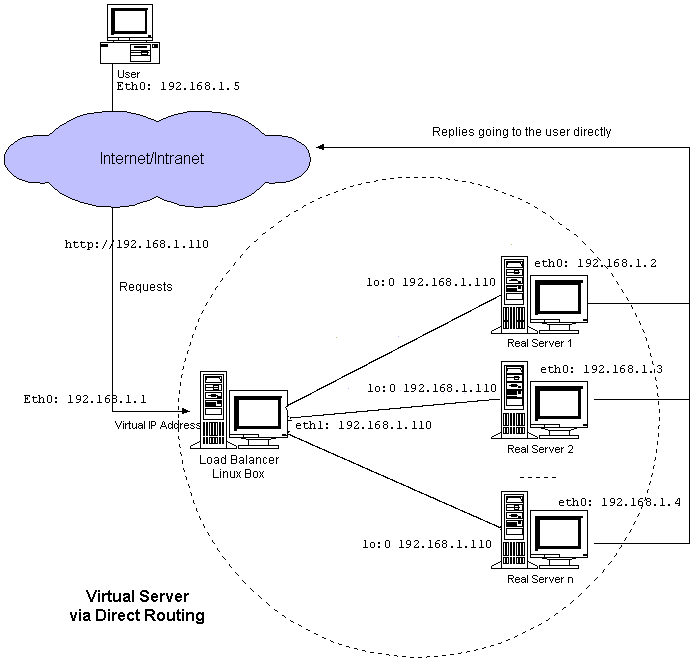
1. Provision yourself some servers using Debian or Ubuntu just for the keepalived stuff. I find that redhat has issues with compiling and its a bit slow. Your DB’s can be whatever distro you want.
Note. Ensure that you have two nics setup on your VM’s and that they are on the same vlan’s. This setup is single armed. If you are Doing NAT you will need two VLANS.
2. COMPILE YOUR KEEPALIVED AND SETUP
If you decided to use debian you will need the following packages to compile from source. I would recommend compiling from source, so you don’t have to worry about updates from the OS repo affecting your environments by accident. Ensure that you have the Kernel Headers installed, as you will need them.
apt-get install gcc libssl-dev libpopt-dev libnl-dev ipvsadm
./configure –with-kernel-dir=/usr/src/linux-headers-2.6.35-23-server/
make && make install
Once this installed you will need to make some modification the startup scripts
mv /etc/init.d/keepalived /etc/init.d/keepalived.bak
cd /etc/init.d/
ln -s /usr/local/etc/rc.d/init.d/keepalived keepalived
mv /usr/sbin/keepalived /usr/sbin/keepalived.original
cd /usr/sbin
ln -s /usr/local/sbin/keepalived keepalived
Update the /etc/init.d/keepalived script
updated /etc/init.d/keepalived
=================================
#!/bin/sh
#
# Startup script for the Keepalived daemon
#
# processname: keepalived
# pidfile: /var/run/keepalived.pid
#config: /usr/local/etc/keepalived
# chkconfig: – 21 79
# description: Start and stop Keepalived
PATH=/sbin:/bin:/usr/sbin:/usr/bin
DAEMON=/usr/local/sbin/keepalived
NAME=keepalived
DESC=keepalived
CONFIG=/etc/keepalived/keepalived.conf
# Source function library
#. /etc/rc.d/init.d/functions
. /lib/lsb/init-functions
# Source configuration file (we set KEEPALIVED_OPTIONS there)
#. /etc/sysconfig/keepalived
. /usr/local/etc/sysconfig/
====================================================
Next you will need to edit the file below on both lvs servers
/etc/sysctl.conf on both LVS1 and LVS2 save the file and run ‘sysctl -p‘ to load it to the running config
net.ipv4.ip_forward = 1
==========================================
3. Configure your nics on LVS1 and LVS2
/etc/network/interfaces (The ip’s listed below are example only please dont use them hoping it will work)
# This file describes the network interfaces available on your system
# and how to activate them. For more information, see interfaces(5).
# The loopback network interface
auto lo
iface lo inet loopback
#This line adds a static route for the entire subnet so traffic can reach the real servers #properly, this line is not necessary, however if the packets are dropping at the destination, #this line helps correct that, it usually better to have this in place.
up ip route add 172.16.0.1/26 dev eth0;:
# The primary network interface
auto eth0 eth1
iface eth0 inet static
address 172.16.0.1
netmask 255.255.255.192
network 172.16.0.1
broadcast 172.16.0.1
gateway 172.16.0.1
# dns-* options are implemented by the resolvconf package, if installed
dns-nameservers 172.16.0.1 172.16.0.1
dns-search sa.it.nicktailor.com
iface eth1 inet static
#This interface is on the same vlan as the primary eth0 interface on purpose. This i#nterface is soley used by keepalived as the sync interface / hearbeat for keepalived #daemon to sync to the second director lvs2.
address 172.16.98.2
#This ip should be an non routable address you define, just make sure that lvs2 is on the #same subnet as this non routeble address, so if this is lvs1 then lvs2 will be 172.16.98.3 #kind of thing.
netmask 255.255.255.0
=============================================================
4. Now what I have done is setup a reload script that will update LVS2 upon reload so I dont have to keep updating both LVS server everytime I have to do a graceful reload, not sure why keepalive has not implemented this feature yet. Developer, don’t think like systems engineers and vice versa.
- . setup ssh keys on both server so that root can ssh to lvs2 via ssh key
- Login into destination server
- cd /root/.ssh
- run ‘ssh-keygen -t rsa’
- run ‘cat id_rsa.pub > authorized_keys && chmod 600 authorized_keys’
- Login into to lvs1
- cd /root/.ssh
- copy both id_rsa fils into this directory from lvs2
- run ‘cat id_rsa.pub > authorized_keys && chmod 600 authorized_keys’
You should be able to ssh now ‘ssh root@hostname‘ and it should login. If it didn’t go google why 😛
5. A) Setup keepalived and automating the reload process
Login into LVS1
cd /etc/keepalived/
mkdir conf.d/
mkdir backups/
Create a keepalived.conf in /etc/keepalived/ and copy past the following in it, you will need to update the varibles according to your own setup
sample keepalived.conf
http://www.nicktailor.com/files/keepalived.conf.lvs1
http://www.nicktailor.com/files/keepalived.conf.lvs2
##WARNING:
#If this configuration is copied over to the SLAVE LVS as is stuff will EXPLODE
### There are elements within that need to stay unique on each server.
### Specifically:
### -lvs id
### -state
### -priority
#########################################################################
global_defs {
notification_email {
nick.tailor@nicktailor.com
}
notification_email_from root@lvs1
smtp_server 127.0.0.1
smtp_connect_timeout 30
lvs_id lvs1
}
vrrp_instance external_linux {
state MASTER
smtp_alert
interface eth0
lvs_sync_daemon_interface eth0
virtual_router_id 42
priority 150
advert_int 1
preempt
authentication {
auth_type PASS
auth_pass nicktailor
}
virtual_ipaddress {
#VIP’s are listed and or Gateway ip is listed here if using NAT for DB boxes
172.16.10.1
}
virtual_server 172.16.10.1 3306 {
delay_loop 10
lb_algo rr
lb_kind DR
protocol TCP
# persistence_timeout 30 (this is not needed for db with replication setup,
# only enabled if you absolutely have to)
#When removing servers from the pool comment starting below this line
real_server 142.103.18.2 3306 {
MISC_CHECK {
misc_path “/root/keepalived/dbcheck.sh 142.103.18.2”
misc_timeout 30
}
}
#make sure to comment above bracket when removing above server from pool
real_server 142.103.18.3 3306 {
MISC_CHECK {
misc_path “/root/keepalived/dbcheck.sh 142.103.18.2”
misc_timeout 30
}
}
#make sure to comment above last bracket when removing above server from pool, do not comment out below bracket
}
================================================================
I have broken the keepalived.conf file into three sections for the purpose of automating & config updates to LVS2
Create
/etc/keepalived/head <- Contains the Global LVS directives for the directors(director means LVS1 or LVS2) there are links below for example files.
==================
Warning: Directives within the GLOBAL section MUST differ on each server in a failover setup!!!
Global-Directives
* Unique Directives:
- o lvs_id – { name of the LVS, usually lvs1-domain)
- o state – { MASTER or BACKUP depends on what is role of this server }
- o priority – { This value must be higher on master for example 100 on MASTER and 50 on BACKUP }
* Shared Directives
- o virtual_router_id – { this should be differnet for each LVS configuration, tcpdump -n -p 112, will show you which ones are in use }
- o vrrp_instance – { name of instance, usually domain, or domain_eth0 }
Example /etc/keepalived/head (whatever you put in your keepalived.conf for the globaldefs put in your head file copy past it here is a sample ones.
http://www.nikktailor.com/files/headfilelvs1
http://www.nicktailor.com/files/headfilelvs2
====================
global_defs {
notification_email {
nick.tailor@nicktailor.com
}
notification_email_from root@lvs1.nicktailor.com
smtp_server 127.0.0.1
smtp_connect_timeout 30
lvs_id lvs1
}
vrrp_instance external_linux {
state BACKUP
smtp_alert
interface eth0
lvs_sync_daemon_interface eth1
virtual_router_id 42
priority 50
advert_int 1
preempt
authentication {
auth_type PASS
auth_pass nicktailor
}
===================
/etc/keepalived/virtual_ips.conf <- Contains the VIP ip’s, whatever you have in your keepalived.conf create this file and copy paste it.
http://nicktailor.com/files/virtual_ips.conf
================================
virtual_ipaddress {
#VIP’s are listed and or Gateway ip is listed here if using NAT for DB boxes
172.16.10.1 #Development VIP
172.16.10.2 #Production VIP
}
================================
inside the conf.d/ directory you will have the real server config. Make sure you never have duplicates as the reload script will mess up your keepalived.conf file if do and you can bring down your VIPS
http://www.nicktailor.com/files/testmschk.conf (Example)
/etc/keepalived/conf.d/testmschkscript.conf
==================================================
#reload config with ‘/etc/init.d/keepalive_reload’ this will update lvs2 with changes automatically
#DO NOT RELOAD CONFIG FROM LVS2
#To see pool use ‘watch ipvsadm -L -n’
#’ip addr’ will show you which lvs the vip is bound to
virtual_server 172.16.10.1 3306 {
delay_loop 10
lb_algo rr
lb_kind DR
protocol TCP
# persistence_timeout 30 (this is not needed for db with replication setup, only enabled if you absolutely have to)
#this is the failover server if it fails over to this traffic is forced there are no checks done on this server by keepalived
sorry_server 142.103.18.2 3306
#When removing servers from the pool comment starting below this line
real_server 142.103.18.1 3306 {
MISC_CHECK {
misc_path “/root/keepalived/dbcheck.sh 142.103.18.1”
misc_timeout 30
}
}
#make sure to comment above last bracket when removing above server from pool, do not comment out below bracket
}
================================================================
B) Automation Reload Script
create the following file /etc/init.d/keepalivedreload and give it executable permissions.
create /etc/keepalived/backups directory as well.
/etc/init.d/keepalivedreload (LVS1)
http://www.nicktailor.com/files/keepalivedreloadlvs1
a) this will copy the virtual ips file and conf.d directory to lvs2 and reload the config lvs2 and make a backup of the config prior to update.
===============================
#!/bin/bash
KADIR=/etc/keepalived
BACKUPFILE=”$KADIR/backups/`date +’%Y%m%d-%H%M’`.conf”
CONFFILE=$KADIR/keepalived.conf
echo Making a backup of the conf file as $BACKUPFILE.gz
cp $KADIR/keepalived.conf $BACKUPFILE
gzip $BACKUPFILE
echo “Adding gateways and virtual IPs…”
cat $KADIR/head $KADIR/virtual_ips.conf > $CONFFILE
echo “}” >> $CONFFILE
#echo “}” >> $CONFFILE
echo “##################################################” >> $CONFFILE
echo “Adding virtual servers…”
for i in $KADIR/conf.d/*
do
cat $i >> $CONFFILE
done
echo “Copying gateways, virtual IPs, and virtual servers to lvs2nicktailor.com…”
scp $KADIR/virtual_ips.conf root@lvs2nicktailor.com:/etc/keepalived/
for i in $KADIR/conf.d/*
do
scp $i root@lvs2nicktailor.com:/etc/keepalived/conf.d/
done
echo “Reloading keepalived config…”
/etc/init.d/keepalived reload
echo “Issuing reload on lvs2nicktailor.com…”
echo “==============================”
ssh root@lvs2nicktailor.com /etc/init.d/keepalived_reload
echo “Done.”
============================================
Now I have made the second one so that you can’t make reloads updates to the primary lvs from the secondary, just because of human error. You’re free to do this however you please. I found this way to be beneficial.
(LVS2) /etc/init.d/keepalivedreload this script will just make a backup and reload on lvs2 and not update back to lvs1.
http://www.nicktailor.com/files/keepalivedreloadlvs2
====================================
#!/bin/bash
KADIR=/etc/keepalived
BACKUPFILE=”$KADIR/backups/`date +’%Y%m%d-%H%M’`.conf”
CONFFILE=$KADIR/keepalived.conf
echo Making a backup of the conf file as $BACKUPFILE.gz
cp $KADIR/keepalived.conf $BACKUPFILE
gzip $BACKUPFILE
echo “Adding gateways and virtual IPs…”
cat $KADIR/head $KADIR/virtual_ips.conf > $CONFFILE
echo “}” >> $CONFFILE
#echo “}” >> $CONFFILE
echo “##################################################” >> $CONFFILE
echo “Adding virtual servers…”
for i in $KADIR/conf.d/*
do
cat $i >> $CONFFILE
done
#echo “Copying gateways, virtual IPs, and virtual servers to lvsdevl22.webi.it.ubc.ca…”
#scp $KADIR/virtual_ips.conf
#root@lvs2nicktailor.com:/etc/keepalived/
#for i in $KADIR/conf.d/*
#do
#scp $i root@lvs2nicktailor.com:/etc/keepalived/conf.d/
#done
echo “Reloading keepalived config…”
/etc/init.d/keepalived reload
#echo “Issuing reload on lvs2nicktailor.com…”
#echo “==============================”
#ssh root@lvs2nicktailor.com /root/bin/keepalive_reload
#ssh root@lvs2nicktailor.com /etc/init.d/keepalived reload
echo “Done.”
6. Test the reload by running it and seeing if the upates take effect from lvs1 to lvs2. You should see the keepalived.conf and /etc/keepalived/conf.d directory all matching.
MYSQL DATABASE SERVER DEPLOYMENT AND REPLICATION SETUP
1. Provision your mysql DB servers instal mysql
2. Ensure that your DB servers are on the same vlan as the LVS
3. Configure the nics
4. configure the loopback interface so the VIP is bound to it, since we are doing Direct ROUTE
IE. redhat
/etc/sysconfig/network-scripts/ifcfg-lo:0
=================
DEVICE=lo:0
IPADDR=142.103.18.1
NETMASK=255.255.255.255
# If you’re having problems with gated making 127.0.0.0/8 a martian,
# you can change this to something else (255.255.255.255, for example)
ONBOOT=yes
NAME=loopback
5. Update /etc/sysctl.conf
net.ipv4.conf.default.arp_ignore=1
net.ipv4.conf.default.arp_announce=2
net.ipv4.conf.all.arp_ignore=1
net.ipv4.conf.all.arp_announce=2
and run ‘sysctl -p‘
Note: The reason for this is it will make sure the server doesn’t loop back and start ARP requests for the VIP.
MYSQL REPLICATION SETUP – i was too lazy to write it all out so I found his great link to explain how to set it up
http://www.howtoforge.com/mysql_master_master_replication
=============================================
Master 1/Slave 2 ip: 192.168.16.4
Master 2/Slave 1 ip : 192.168.16.5
Step 2:
On Master 1, make changes in my.cnf:
[mysqld]
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
old_passwords=1
log-bin
binlog-do-db=<database name> # input the database which should be replicated
binlog-ignore-db=mysql # input the database that should be ignored for replication
binlog-ignore-db=test
server-id=1
[mysql.server]
user=mysql
basedir=/var/lib
[mysqld_safe]
err-log=/var/log/mysqld.log
pid-file=/var/run/mysqld/mysqld.pid
Step 3:
On master 1, create a replication slave account in mysql.
mysql> grant replication slave on *.* to ‘replication’@192.168.16.5 \
identified by ‘slave’;
and restart the mysql master1.
Step 4:
Now edit my.cnf on Slave1 or Master2 :
[mysqld]
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
old_passwords=1
server-id=2
master-host = 192.168.16.4
master-user = replication
master-password = slave
master-port = 3306
[mysql.server]
user=mysql
basedir=/var/lib
[mysqld_safe]
err-log=/var/log/mysqld.log
pid-file=/var/run/mysqld/mysqld.pid
Step 5:
Restart mysql slave 1 and at
mysql> start slave;
mysql> show slave status\G;
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.16.4
Master_User: replica
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: MASTERMYSQL01-bin.000009
Read_Master_Log_Pos: 4
Relay_Log_File: MASTERMYSQL02-relay-bin.000015
Relay_Log_Pos: 3630
Relay_Master_Log_File: MASTERMYSQL01-bin.000009
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 4
Relay_Log_Space: 3630
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 1519187
1 row in set (0.00 sec)
Above highlighted rows must be indicate related log files and Slave_IO_Running and Slave_SQL_Running: must be to YES.
Step 6:
On master 1:
mysql> show master status;
+————————+———-+————–+——————+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+————————+———-+————–+——————+
|MysqlMYSQL01-bin.000008 | 410 | adam | |
+————————+———-+————–+——————+
1 row in set (0.00 sec)
The above scenario is for master-slave, now we will create a slave master scenario for the same systems and it will work as master master.
Step 7:
On Master2/Slave 1, edit my.cnf and master entries into it:
[mysqld]
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
# Default to using old password format for compatibility with mysql 3.x
# clients (those using the mysqlclient10 compatibility package).
old_passwords=1
server-id=2
master-host = 192.168.16.4
master-user = replication
master-password = slave
master-port = 3306
log-bin #information for becoming master added
binlog-do-db=adam
[mysql.server]
user=mysql
basedir=/var/lib
[mysqld_safe]
err-log=/var/log/mysqld.log
pid-file=/var/run/mysqld/mysqld.pid
Step 8:
Create a replication slave account on master2 for master1:
mysql> grant replication slave on *.* to ‘replication’@192.168.16.4 identified by ‘slave2’;
Step 9:
Edit my.cnf on master1 for information of its master.
[mysqld]
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
# Default to using old password format for compatibility with mysql 3.x
# clients (those using the mysqlclient10 compatibility package).
old_passwords=1
log-bin
binlog-do-db=adam
binlog-ignore-db=mysql
binlog-ignore-db=test
server-id=1
#information for becoming slave.
master-host = 192.168.16.5
master-user = replication
master-password = slave2
master-port = 3306
[mysql.server]user=mysqlbasedir=/var/lib
Step 10:
Restart both mysql master1 and master2.
On mysql master1:
mysql> start slave;
On mysql master2:
mysql > show master status;
On mysql master 1:
mysql> show slave status\G;
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.16.5
Master_User: replica
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: Mysql1MYSQL02-bin.000008
Read_Master_Log_Pos: 410
Relay_Log_File: Mysql1MYSQL01-relay-bin.000008
Relay_Log_Pos: 445
Relay_Master_Log_File: Mysql1MYSQL02-bin.000008
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 410
Relay_Log_Space: 445
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 103799
1 row in set (0.00 sec)
ERROR:
No query specified
===========================================================================
NOW SETUP MYSQL FOR KEEPALIVED TO BE ABLE TO WRITE TO IT.
Note – if you setup replication correctly, this will replicate over to your secondary DB and you wont have to worry about setting this up on your secondary.
1. this is so keepalived msc_chk will be able to test to see if the db can be written to and it put a timestamp in the tables.
– You are now creating a DB for keepalived to write to
Copy Paste at MySQL prompt logged in as MySQL root
===========================================================
CREATE DATABASE `healthcheck` DEFAULT CHARACTER SET latin1 COLLATE latin1_swedish_ci;
CREATE TABLE `healthcheck`.`keepalived` (
`id` INT( 11 ) NOT NULL AUTO_INCREMENT ,
`data` VARCHAR( 100 ) NULL ,
PRIMARY KEY ( `id` )
) ENGINE = MYISAM;
CREATE TABLE `healthcheck`.`keepalived2` (
`id` INT( 11 ) NOT NULL AUTO_INCREMENT ,
`data` VARCHAR( 100 ) NULL ,
PRIMARY KEY ( `id` )
) ENGINE = MYISAM;
use healthcheck;
insert into keepalived (data) values (“hello”);
insert into keepalived (data) values (“hello”);
insert into keepalived2 (data) values (“hello”);
insert into keepalived2 (data) values (“hello”);
GRANT ALL ON *.* TO ‘lvs1’@’lvs1.nicktailor.com’ identified by ‘password’;
GRANT ALL ON *.* TO ‘lvs2’@’lvs2.nicktailor.com’ identified by ‘password’;
============================================================
2. A)Log back into LVS1
B)Also do the same for LVS2 with below steps.
touch /var/log/keepalived/dbcheckprod.log
create a directory called /root/keepalived/
– this is where your msck_chk script lives
– it will check tcp, port, mysql service and table write) 3 times and log it if it fails keepalived will fail to the secondary
– please note the UPDATE table section in this script needs to match the mysql ID you have in mysql below in the script
/root/keepalived/dbcheck.sh
http://www.nicktailor.com/files/dbcheck.sh
=======================================
#!/usr/bin/perl
#use strict;
#use warnings;
use DBI;
use POSIX;
#use Mysql;
use Sys::Hostname;
$host = $ARGV[$0] ;
$lvs_host=hostname;
$database = “healthcheck”;
$tablename = “keepalived”;
$user = “lvs1”;
$pw = “password”;
$dbinfo = “DBI:mysql:$database;host=$host;mysql_connect_timeout=2”;
$timestamp = strftime “%b%e %Y %H:%M:%S”, localtime;
$logdir = “/var/log/keepalived/dbcheckprod.log”;
open (LOG_FILE,”>>$logdir”);
if ($lvs_host eq “lvs1.nicktailor.com”)
{
$tablename = “keepalived”;
}
elsif ($lvs_host eq “lvs2.nicktailor.com”)
{
$tablename = “keepalived2”;
}
#$connect = Mysql->connect($host, $database, $user, $pw);
#$dbh = DBI->connect($dbinfo,$user,$pw,{ RaiseError => 1 }) or die $DBI::errstr;
$connect_fail = 0;
print LOG_FILE “\n\n\n$timestamp\n”;
print LOG_FILE “$host\n”;
# try to connect to db server
# exit with error if db connection fails 3x
for ($count=0; $count <= 2; $count++)
{
$dbh = DBI->connect($dbinfo,$user,$pw, {RaiseError => 0, PrintError=>0});
print LOG_FILE “Outer loop round $count: error is ” . $DBI::err . “\n”;
if (!$DBI::errstr)
{
print LOG_FILE “connected!\n”;
$myquery = “UPDATE $tablename SET data=’$timestamp’ WHERE id = ‘1’”;
$fail=0;
for ($count = 0; $count <= 2; $count++)
{
$result = $dbh->do($myquery);
if ($result > 0)
{
print LOG_FILE “$count “;
print LOG_FILE “success!\n”;
}
else
{
print LOG_FILE “$count “;
print LOG_FILE “fail!\n”;
$fail++;
}
sleep(8);
}
$dbh->disconnect();
if ($fail == 0)
{
print LOG_FILE “success because failed $fail times\n”;
print LOG_FILE “exit 0 from table test\n”;
close (LOG_FILE);
exit 0;
}
else
{
print LOG_FILE “failed $fail times\n”;
print LOG_FILE “exit 1 from table test\n”;
close (LOG_FILE);
exit 1;
}
}
else
{
$connect_fail++;
print LOG_FILE “connnect_fail = $connect_fail\n”;
}
sleep(8);
}
if ($connect_fail > 0)
{
print LOG_FILE “failed $connect_fail times!”;
print LOG_FILE “exit 1 from connect_fail test\n”;
close (LOG_FILE);
exit 1;
}
#else clause may not be necessary because if connect_fail < 3 then table check code would take care of exits
else
{
print LOG_FILE “connect fail is 3 but still in else clause?”;
print LOG_FILE “exit 0 from connect test\n”;
close (LOG_FILE);
exit 0;
}
================================================================
MYSQL REPLICATION SYNCHORIZATION/FAILURE PROTECTION
================================================================
– So we want to make sure that MYSQL in the event restarts doesnt allow traffic until both databases servers are caught with replication.
1. Log into mysql server
2. disabled mysql init startup script. If your on redhat its simply ‘chkconfig mysql off’
3. edit /etc/rc.local and add the line
/etc/init.d/mysql2 to the end and save it
3. Now your going to setup your start up script that will make sure the replication is caughtup before it allows traffic to the DB
a) Make sure you have iptables setup on your DB servers and that the rules are setup to allow lvs1 and lvs2 ips to connect on port 3306
/etc/init.d/mysql2
http://www.nicktailor.com/files/mysql2
==================================
#!/bin/bash
# This will script delete remove the lvs ips if they exist and then add them so there are no duplicate entries
# It greps for the seconds behind the Master until it hits ZERO if its at ZERO then it will allow the LVS server to connect to the DB.
# It will also send out an email if replication is broken and keep traffic blocked. My advice before setting this up is get familar with it # and test before using.
# Make healthcheck fail
IPTABLES=”$(which iptables)”
# Make sure rule doesn’t exist before we add so we don’t double up
$IPTABLES -D RH-Firewall-1-INPUT -s <lvs1ip> -p tcp –dport 3306 -j ACCEPT
$IPTABLES -D RH-Firewall-1-INPUT -s <lvs2ip> -p tcp –dport 3306 -j ACCEPT
# start mysql
service mysql start
GREP=”$(which grep)”
CUT=”$(which cut)”
SLEEP=”$(which sleep)”
# start values
POS=4
#EXEC_POS=5
#I=0
ECHO=”/bin/echo”
#$ECHO “Waiting for Replication “
#while ( test “$READ_POS” != “$EXEC_POS” )
$SLEEP 10
while [ “$POS” -gt 0 ];
do
POS=`/usr/bin/mysql -Bse ‘show slave status\\G’ -ppassword | grep ‘Seconds_Behind_Master’ | grep -o -E ‘[0-9]*$’`
if [[ $POS != [0-9]* ]];
then
$ECHO “Replication is broken so keeping port 3306 blocked.”
mail -s ‘Replication broken, keeping port 3306 blocked’ nicktailor\@nicktailor.com < ~root/mysqlstopped.txt
exit
fi
# READ_POS=`$ECHO $POS | $CUT -d\ -f1`
# EXEC_POS=`$ECHO $POS | $CUT -d\ -f2`
$ECHO “Seconds behind master is $POS”
#$ECHO “READ_POS is $READ_POS”
#$ECHO “EXEC_POS is $EXEC_POS”
# Output every ~10 sec
# if ( test “`$ECHO $(($I%10))`” -eq “0” )
# then
# $ECHO “inside timer loop READ_POS is $READ_POS”
# $ECHO “inside timer loop EXEC_POS $EXEC_POS”
# fi
# I=$(($I+1))
$SLEEP 1
done
# Make healthcheck succeed
$IPTABLES -I RH-Firewall-1-INPUT 12 -s <lvs1ip> -p tcp –dport 3306 -j ACCEPT
$IPTABLES -I RH-Firewall-1-INPUT 12 -s <lvs2ip> -p tcp –dport 3306 -j ACCEPT
===============================================================
4. Now we on your secondary DB we want to make sure that in the event a failure occurs the replication is not broken or the data would get out of sync. So we have a script that check replication every 5 seconds via a cron, if replication is broken it will change the DB to read only and send out an alert email.
/root/repl_check/dbhealth.pl
http://www.nicktailor.com/files/dbhealth.pl
======================================
#!/usr/bin/perl
use Sys::Hostname;
use POSIX;
$timestamp = strftime “%b%e %Y %H:%M:%S”, localtime;
$host = hostname;
$email_lock = “/root/email.lck”;
$mysql_socket = “/var/lib/mysql/mysql.sock”;
$show_slave_status = “/root/repl_check/show_slave_status.txt”;
$set_read_only = “/root/repl_check/set_db_read_only.sql”;
$pword = “password”;
# check to see if mysql socket exists. if it exists, means that mysql is running. if mysql not running, don’t need to run slave status check
sub check_mysql_socket
{
# Can’t connect to local MySQL server through socket ‘/var/lib/mysql/mysql.sock
if (-e $mysql_socket)
{
print “MySQL running, will proceed\n”;
return 1;
}
else
{
print “MySQL not running, will do nothing\n”;
return 0;
}
}
# check to see if email.lck exists. if it does, that means email has been sent, no need to keep resending it
sub check_email_lock
{
if (-e $email_lock)
{
print “email file exists\n”;
return 1;
}
else
{
print “no email file exists\n”;
return 0;
}
}
sub stop_mysql
{
print “**Show Read Only Status**\n”;
system(“mysql -p$pword < $set_read_only”);
if (check_email_lock)
{
print “email lock exists, keep email lock, no email will be sent “;
}
else
{
system (“mail -s ‘mysql stopped on $host’ nicktailor\@nicktailor.com < ~root/mysqlstopped.txt”);
system (“touch $email_lock”);
print “email sent, email lock created\n”;
}
}
print $timestamp . “\n”;
# if MySQL is running
if (check_mysql_socket)
{
# for testing with text file
# $last_io_errno = `less develscripts/slavestatus_master_down.txt | grep Last_IO_Errno | /usr/bin/awk ‘{print \$2}’`;
# $last_sql_errno = `less develscripts/slavestatus_master_down.txt | grep Last_SQL_Errno | /usr/bin/awk ‘{print \$2}’`;
system (“/usr/bin/mysql -Bse ‘show slave status\\G’ -p$pword > $show_slave_status”);
$last_io_errno = `less $show_slave_status | grep Last_IO_Errno | /usr/bin/awk ‘{print \$2}’`;
$last_sql_errno = `less $show_slave_status | grep Last_SQL_Errno | /usr/bin/awk ‘{print \$2}’`;
$slave_io_running = `less $show_slave_status | grep Slave_IO_Running | /usr/bin/awk ‘{print \$2}’`;
$slave_sql_running = `less $show_slave_status | grep Slave_SQL_Running | /usr/bin/awk ‘{print \$2}’`;
# trim newline character
chomp($last_io_errno);
chomp($last_sql_errno);
chomp($slave_io_running);
chomp($slave_sql_running);
print “last io error is ” . $last_io_errno . “\n”;
print “last sql errno is ” . $last_sql_errno . “\n”;
print “slave io running is ” . $slave_io_running . “\n”;
print “slave sql running is ” . $slave_sql_running . “\n”;
if (($last_io_errno > 0) && ($last_io_errno != 2013))
{
&stop_mysql;
}
elsif ($last_sql_errno > 0)
{
&stop_mysql;
}
# if slave not running = Slave_IO_Running and Slave_SQL_Running are set to No
elsif (($slave_io_running eq “No”) && ($slave_sql_running eq “No”))
{
&stop_mysql;
}
else
{
if (check_email_lock)
{
system (“rm $email_lock”);
}
print “replication fine or master’s just down, mysql can keep going, removed lock file\n”;
}
}
else
{
print “#2 MySQL not running, will do nothing\n”;
}
print “\n#########################\n”;
==================================================================================
Also create the following files for the above script to work
set_db_read_only.sql
http://www.nicktailor.com/files/
=========================
show variables like “read_only”;
set global read_only=on;
show variables like “read_only”;
=========================
touch show_slave_status.txt
===============================
unset_db_read_only.sql
http://www.nicktailor.com/files/unset_db_read_only.sql
===============================
show variables like “read_only”;
set global read_only=off;
show variables like “read_only”;
===============================
Next setup a cron to run this on the secondary DB however many seconds you like
FINAL SETUP PIECE!!
MYSQL BACKUPS
ON noth DB server you want to have mysql backups running via a cron
For multi-threaded backup and restores of InnoDB and myisam check out my http://www.nicktailor.com/?p=270 post here.
/root/backup/mysqldumpbackup.sh
http://www.nicktailor.com/files/mysqldumpbackup.sh
==============================
#Backup multiple MySQL databases into separate files and one full backup of all of them and then tars them in to archive directory and
#retains 7 day archives
#!/bin/bash
# backup each mysql db into a different file, rather than one big file
# as with –all-databases – will make restores easier
USER=”root”
PASSWORD=”password”
OUTPUTDIR=”mysqldumpoutput”
MYSQLDUMP=”/usr/bin/mysqldump”
MYSQL=”/usr/bin/mysql”
purgedir=”mysqldumptars”
now=`date ‘+%Y-%m-%d-%H-%M-%S’`
# clean up any old backups – save space
/bin/rm “OUTPUTDIR/*bak” > /dev/null 2>&1
# does a all database mysql dump backup
$MYSQLDUMP –single-transaction –force –opt –user=$USER –password=$PASSWORD –all-databases > “$OUTPUTDIR/alldbdump.bak”
# get a list of databases
databases=`$MYSQL –user=$USER –password=$PASSWORD -e “SHOW DATABASES;” | tr -d “| ” | grep -v Database`
# dump each database in turn
for db in $databases; do
echo $db
$MYSQLDUMP –single-transaction –force –opt –user=$USER –password=$PASSWORD –databases $db > “$OUTPUTDIR/$db.bak”
done
#Backup section
#===================
#this make a tar of the new separate dumpfiles with a time stamp and moves the tar to separate directory upon completion
cd mysqldumpoutput/
/bin/tar -zcvf mysqldump.tar ./*
/bin/mv mysqldumpoutput/mysqldump.tar /dd02/mysqldumptars/mysqldump_${now}.tar
#This deletes any tar that is more than 7 days old for the dump backups
/usr/bin/find ${purgedir} -maxdepth 1 -name “mysqldump_*” -mtime +6 -exec rm -rf {} \; -ls
===============================================================
I HOPE YOU ENJOYED THIS TUTORIAL AND SETUP I KNOW ITS LONG. 🙂
If you log into LVS1 now and run
watch ipvsadm -L you should see your servers
To see LVS pool type ‘watch ipvsadm -L -n’ <–This shows all VIPS and real servers bound to them
LVS-HINTS: If you want to watch a specific VIP only:
” watch -n1 ‘ipvsadm -L -n|grep -A$N $VIP:$PORT’ ” <– this will run the specified command updating every 1 second.
Replace $VIP with the virtual IP $PORT with the service and $N with the number of real servers, ie ” watch -n1 ‘ipvsadm -L -n | grep -A2 192.168.0.1:80’ ”
Eg View – ‘watch ipvsadm -L -n’
=============================================================================================
Every 2.0s: ipvsadm -L -n Tue Oct 25 16:47:22 2011
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 172.16.10.1:3306 wlc <—-VIP
-> 142.103.18.1:3306 Route 1000 0 45 <–Real Server
==============================================================================================
‘ip addr’ will show you which lvs the vip is bound to
To Stop keepalived ‘/etc/init.d/keepalived stop’
To start keepalived ‘/usr/local/sbin/keepalived’
===============================
If you have questions you can email me at nick@nicktailor.com